







Please enter the answer below before you can view the full text.
2-1=
The structure from motion (SfM) is a reconstruction algorithm that recovers the pose of cameras and three-dimensional structure of the target by calculating the image matching relationship. An incremental SfM algorithm based on weighted scene graph was proposed. Firstly, a weighted scene graph was established, which quantified the matching relationship between image pairs. Secondly, an optimal initial seed pair of degree perception was searched based on the edge weights of the weighted scene graph. Finally, the next optimal image candidate set was constructed according to the connectivity of the reconstructed vertices, and an evaluation algorithm based on the vertex degree and feature point distribution was designed to search for the next optimal image in the candidate set. The experimental results on multiple public datasets show that the proposed algorithm outperforms existing advanced structure from motion algorithms in terms of reconstruction quality, camera calibration rate and point cloud generation quantity. Compared with the benchmark comparison algorithms, the average reconstruction time on different datasets is reduced by at least 19%, and the point cloud generation rate is increased by at least 21%.
In order to improve the winding image resolution of the optical fiber coils and reduce the memory and computational overhead caused by the deep learning model, a dual-branch network that can simultaneously extract the gradient information and image information was proposed. The image features in the network path were extracted by using the advantages of speediness and light weight of lightweight residual blocks, and the multi-stage residual feature transfer mechanism was also introduced. Under the combined action of gradient information and feature transfer, the network could retain the rich geometric structure information, which made the edge details of the reconstructed image clearer. The experimental results show that, the proposed model achieves superior performance with fewer parameters and a running time of 0.018 s. Under the double, triple and quadruple scale factors, the peak signal-to-noise ratio is 44.08 dB, 41.35 dB and 38.97 dB, respectively and the structural similarity index is 0.985 8, 0.979 3 and 0.976 9, respectively, which are both superior to other existing methods and provide a strong guarantee for subsequent quality detection of optical fiber coils.
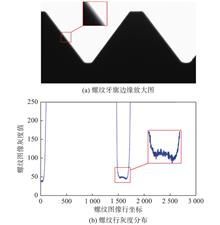
In order to improve the measurement accuracy of machine vision thread, an evaluation method based on thread image quality was established. Through the analysis of the line gray-level distribution of the thread gray images and the optical imaging characteristics of the thread, the mechanism of the thread image edge distortion caused by the helix angle was revealed. Based on the analysis of the performance of various thread image evaluation methods, the evaluation algorithm L-yakuo based on the thread edge was adopted to calculate the evaluation value of multiple thread images with different object distances. Finally, the experimental comparison and analysis of the M14×2, M20×2.5 thread angle obtained by machine vision and the thread angle obtained by contact measuring instrument were carried out. The experimental results show that after the clearest tooth profile image is obtained by the L-yakuo algorithm, the machine vision thread angle is calculated, and the accuracy of the thread angle of M14×2 and M20×2.5 is improved 9′33′′ on average. With the help of L-yakuo algorithm, it can sensitively reflect the definition of thread profile, which basically meets the evaluation requirements of thread image definition. The changes of the evaluation value are basically the same as the changes of the relative error of the thread angle, and the evaluation value has the characteristics of high accuracy and easy to calculate.
With the development of computer technology, the target tracking methods based on deep learning have become an important research direction in the field of computer vision. However, the target tracking methods still face great challenges in complex environment such as background interference and color proximity. Compared with the traditional color images, the hyperspectral images contain rich radiation, spatial and spectral information, which can effectively improve the accuracy of target tracking. A method was proposed in combination with attention mechanism and additive angular margin loss (AAML) to perform target tracking for hyperspectral images. The features of different combinations of bands were extracted by fused multi-domain neural networks, and then the fused attention mechanism model was designed to make the similar features from different combinations of bands integrated and strengthened. Therefore, when the target background color was similar, the network would pay more attention to the target object, which made the tracking results more accurate. On this basis, in order to make the distinction between target and background more discriminative, the AAML was adopted as loss fuction to effectively reduce the intra-class distance of similar samples, increase the inter-class distance between centers of positive and negative samples, and improve the network accuracy and stability during the training process. The experimental results show that the accuracy and success rate of the two tracking accuracy evaluation indexes can be improved by 1.3% and 0.3% respectively, which has more advantages than other methods.
The emergence and development of hyper-spectral satellites provide a new technical means for remote sensing and mapping. Compared with the traditional satellite images, the hyper-spectral satellite images contain the richer spectral information, which can carry out more accurate identification, classification, positioning and mapping of target objects. Taking the hyper-spectral satellite images provided by the Zhuhai No. 1 hyper-spectral satellite (OHS-C) as the sample, the accurate identification, enhanced marking and area measurement of forest and water were realized by combing ground clutter reflection spectrum with adaptive algorithm. The ratio method was used to process the spectrum, and the influence of atmospheric conditions and time as well as season on the spectrum can be removed without the complex calibration. The experimental results show that the specificity and sensitivity of identification of forest and water is higher than 97%, respectively. Based on the proposed identification model, the calculated total area of the official waters of Xili Reservoir is about 4.6 km2, and the error with the official data is only about 0.144 6 km2. The green area of Qi'ao Island is calculated to be 22.171 3 km2, and the total area of the island is 23.8 km2. According to the calculation of 90% of the green area, the error is less than 0.751 3 km2, and the error mainly comes from the insufficient spatial resolution of commercial satellites.
The current energy-saving lighting control algorithm still falls into the problem of local optimum. In order to seek for the global optimal solution and improve the energy-saving effect of indoor lighting, a genetic simulated annealing algorithm was designed to optimize the control parameters of lighting system. The local search ability of the algorithm was enhanced by simulated annealing treatment of excellent individuals after genetic manipulation. According to the number of iterations and the fitness of the population, the genetic probability was adaptively adjusted so that the algorithm could enrich the population diversity in the early stage and avoid the prematurity of the algorithm. An illumination model based on artificial neural network was proposed to calculate the indoor illumination distribution and evaluate the illumination comfort, which provided a basis for constructing the fitness function of optimization algorithm. Through simulation experiments, the genetic simulated annealing algorithm was applied in the introduced lighting scenes, and compared with the traditional particle swarm algorithm and genetic algorithm, the lighting energy-saving performance was 5.30% and 13.61% higher respectively.
The deep learning has developed rapidly in the field of detection, but limited by the training data and computing efficiency, the intelligent algorithms of deep learning are not widely used in the edge computing field based on embedded platform, especially in real-time tracking applications. Aiming at this phenomenon, in order to meet the needs of domestic and intelligent technology at the present stage, an improved twin network deep learning tracking algorithm was implemented. The fine-tuning network was added to the feature network to solve the problem that the network model could not be updated online and improve the accuracy of tracking. The center distance penalty term was added into IoUNet loss function to solve the problems of position jumping, existence of convergence blind area and the slow convergence when IoU was the same. The trained network was pruned through channels to reduce the size of network model and improved the loading and running speed of the model. Finally, the model was implemented in real-time on Huawei Atlas200NPU platform. The proposed algorithm accuracy is up to 0.90(IoU>0.7), and the frame rate reaches 66 Hz.
Aiming at the real-time requirements of image fusion in the infrared and visible light, a real-time implementation method to solve the current high-definition or ultrahigh-definition multi-source Laplacian pyramid image fusion was proposed. Based on the video data stream, a parallel processing pipeline architecture of Laplacian pyramid system was designed. The time delay and optimization ideas between the pipelines were analyzed. All the delay time differences were compensated through on-chip cache to achieve the equal length of pipeline and guarantee the integrity of data processing in the whole algorithm. This method could realize 5-level Laplacian pyramid fusion of dual-channel 1080×1920@60 Hz video images on XILINX 7 series field programmable gate array (FPGA) and above. The experimental results show that this real-time method has better fusion effect, with only 10.535 ms of one-frame image fusion and the processing delay is less than 1 ms.
To improve the recognition and classification ability of electro-optical system for dim and small targets, and reduce the dependence of algorithms on hardware platforms and data, an unsupervised classification method was proposed, namely the fine-grained classification method based on deep features clustering. Firstly, the targets were suggested by the extraction of shallow features such as contour, color and contrast. Then, after a super-resolution processing, a convolutional neural network was used to encode the deep features of the target. Furthermore, the principal component analysis based on attention mechanism was adopted to generate the characterization matrix. Finally, the clustering method was used to realize the fine-grained target classification. The experiments were set to verify the classification performance of the deep clustering method based on different neural networks on different data sets. The fine-grained classification performance based on ResNet-34 clustering method reached 92.71% on CIFAR-10 test set. The results show that the fine-grained target method based on deep clustering can achieve the same effect as the strong supervised learning method. In addition, the classification effect of different fine granularity can be realized according to the different numbers of cluster and selection of cluster grades.
Based on the application research of 3D laser scanning technology in railway tank car, the problems of incomplete point cloud and noise which were found during the scanning process were analyzed, and a fast and effective optimized processing method of point cloud was proposed. The new method included sp-H point cloud pre-processing method and Eti-G modeling optimization key algorithm. The verification test results show that the new optimized processing method of point cloud can be used to optimize the noise and incomplete point cloud in a relatively short time and can fast and efficiently reconstruct the model, which improve the applicability of scanning the point cloud under different working conditions, and the efficiency and accuracy of scanning work are also promoted. The related expanded uncertainty of volume measurement results of railway tank car reaches 2.4×10-3, which is the highest accuracy level of railway tank car volume scanning, and provides some references for the development of 3D laser scanning technology.
Due to the complex indoor environment, the visible light location awareness based on Elman neural network has the problems of slow convergence speed and low positioning accuracy. An optimized Elman neural network based on sparrow search algorithm (SSA) was proposed, and a visible light indoor location awareness algorithm was fused with K-means clustering. The database was established for the collected data, the topological structure and connection weight threshold of the Elman were optimized by using SSA, and the training model was designed, so as to solve the problem that the indoor location awareness algorithm based on Elman neural network was easy to fall into the local optimization and improve the convergence speed and robustness. The K-means was used to optimize the classification of database, and the processed data was substituted into the model training to obtain the preliminary prediction results. The preliminary prediction results were substituted into the subclass for secondary training to obtain the final coordinates of predicted position, which further improved the positioning accuracy. The experiment based on three-dimensional space of 0.8 m $ \times $0.8 m $ \times $0.8 m was carried out, and the results show that the average positioning error of the proposed algorithm is 3.22 cm, and the probability of positioning error less than 6 cm is 90%, which improves the positioning accuracy by 7.5% compared with the SSA-Elman algorithm and by 16% compared with the Elman network algorithm.
Aiming at the problems that the traditional visual background extractor (ViBe) algorithm cannot reflect the scene changes in time and has poor adaptability to dynamic scenes, an improved ViBe algorithm was proposed by using randomly selected background samples and 24 neighborhood method to obtain the initial background, which could accelerate the "ghost" ablation. The average adaptive threshold calculation method was adopted to improve algorithm adaptability to external dynamic environment and illumination changes in combination with OTSU method and uniformity measurement method, which retained effective pixels to the greatest extent. In the update phase, the adaptive update factor was introduced, which could effectively reduce the misjudgment probability, so as to enhance algorithm robustness. Finally, the target was more complete through morphological processing and filtering. The standard dataset video was applied to test and compare the improved algorithm. Compared with kernel density estimation (KDE) algorithm, Gaussian mixed model (GMM) algorithm and traditional ViBe algorithm, the indexes of the improved algorithm were greatly improved. The accuracy is improved by 30.44%, 40.72% and 20.95%, respectively and the percentage of wrong classifications is reduced by 43.28%, 40.59% and 29.43%, respectively.
The patch-match algorithm has been widely used in binocular stereo reconstruction due to its low memory consumption and high reconstruction accuracy. However, the traditional patch-match algorithm needs to iteratively calculate the optimal disparity d for each pixel of image in an orderly manner, which resulting in a high running time. In order to solve this problem, a learning-based model on the basis of traditional patch-match algorithm as a guide to reduce the running time and improve the accuracy of stereo reconstruction was introduced. First, the deep learning model was used to output the initial disparity map of each pixel with heteroscedastic uncertainty, which was used to measure the accuracy of the disparity predicted by the network model. Then, the heteroscedastic uncertainty and initial disparity were taken as the prior information of patch-match algorithm. Finally, in the plane refinement step, the heteroscedastic uncertainty of each pixel was used to dynamically adjust its search interval to achieve the goal of reducing the running time. On the Middlebury dataset, compared with the original algorithm, the running time of the improved algorithm is reduced by 20%, and the reconstruction accuracy of the discontinuous region is slightly improved.
When the traditional key frame extraction algorithm is applied to the theodolite image sequence, a large number of unstable tracking image frames will be extracted. In order to better retain the stable tracking measurement information of the target, after analyzing the characteristics of the theodolite image sequence, a key frame extraction algorithm for the theodolite image sequence based on the local maximum was constructed. Firstly, the frame difference of the image sequence was calculated by the algorithm. Then, the Hanning window function was used to smooth the frame difference. Finally, based on the smoothed local maximum of frame difference, the key frame was extracted. The experimental results show that the proposed algorithm can better retain the tracking measurement information of the target compared with the traditional frame difference intensity sorting method. The extracted key frames are more uniformly distributed in the entire tracking measurement image sequence, and the scene information contained is more abundant.
Due to the existence of image motion, the imaging resolution of aerial photoelectric imaging system decreases, which seriously affects the overall performance of aerial photoelectric system. The image motion compensation technology can be used to improve the imaging quality of aerial photoelectric system. The principles of image motion compensation technology for mobile detectors and moving optical elements were analyzed, with emphasis on the high-precision image motion compensation technology based on fast steering mirror (FSM). Through the simplified engineering analysis, the law of follow-up angle of image motion compensation of FSM in parallel optical path and converging optical path was deduced, respectively. In addition, the defocus distance caused by the FSM in the converging optical path were analyzed, and the influence of defocus distance on the wave aberration of the optical system was discussed. The simulation results show that the wave aberration increases linearly with the increase of defocus distance. By analyzing the influence of wave aberration of optical system on its optical modulation transfer function (MTF), the results show that the F number is equal to 8, and at the Nyquist frequency, when the defocus distance is less than 0.1 mm, the declining quantity of optical MTF is within 26.6%.
Aiming at the problems of mutual occlusion between assembly parts, different poses of parts, external light intensity, missed detection of small targets and low detection accuracy of traditional machine vision detection and recognition methods, a parts recognition method based on improved faster recurrent convolutional neural network (RCNN) was proposed. Firstly, the ResNet101 network with better feature extraction was used to replace VGG16 feature extraction network in original Faster RCNN model. Secondly, for the original candidate region network, the two new anchors were added and the aspect ratio of candidate frame was reset to obtain the 15 anchors with different sizes. Then, aiming at the missed detection problems caused by deleting the candidate frame in which the Intersection-over-Union (IoU) was greater than the threshold in traditional non-maximum suppression (NMS) method, the Soft-NMS method was used to replace the traditional NMS method, so as to reduce the missed detection problems in dense regions. Finally, in training model stage, the multi-scale training strategy was adopted to reduce the missed detection rate and improve the accuracy of the model. The experimental results show that the improved Faster RCNN model can achieve 96.1% accuracy, which is 4.6% higher than the original model, and can meet the recognition and detection of parts in complex conditions such as strong illumination and water stain interference.
Aiming at the problems of low efficiency and low accuracy in the detection of internal assembly defects of thermal batteries, a method which could accurately segment the internal battery stack images and accurately identify the types of defects was studied. Firstly, the horizontal and vertical integral projection methods were used to extract the edge features of the target battery stack, and the local adaptive contrast enhancement algorithm was used to enhance the detail texture of the local unclear parts. Then, the gray characteristics of the defect structure were studied and the defect characteristic parameters were calculated and extracted. Finally, the BP neural network and CART decision tree were used to classify and identify the feature parameters, the weight was allocated according to the classification accuracy, and the weighted fusion results were used as the final criterion of the detection. The experimental results show that the accuracy of this method is 98.9% for 2 000 samples, which provides an effective way for X-ray defects detection of thermal batteries.
The ghost imaging is an imaging technology that can penetrate harsh environments such as the heavy fog. Aiming at the problems of more noise and lower image contrast of reconstructed images of traditional ghost imaging, the non-local generalized total variation method was applied for image reconstruction of ghost imaging, and the reconstruction method of computational ghost imaging based on non-local generalized total variation was proposed. The method constructed the non-local correlation weights to design the gradient operator, which was substituted into total variation reconstruction algorithm, so that the reconstructed images could effectively remove the noise while achieving the better detail restoration. The simulations were performed under different conditions, and the peak signal-to-noise ratio of proposed method was improved by about 1 dB compared with other methods, while it had better subjective visual effects. The experimental platform was designed and built to verify the effectiveness of the algorithm. The experimental results verify the superiority of the proposed method in terms of noise removal and detail reconstruction.
Aiming at the defect that the single vision tracking algorithm is easily affected by the occlusion, an object detection and tracking algorithm based on the audio-video information fusion was proposed. The whole algorithm framework included three modules: video detection and tracking, acoustic source localization, audio-video information fusion tracking. The YOLOv5m algorithm was adopted by the video detection and tracking module as the framework of visual inspection, and the unscented Kalman filter and Hungary algorithm were used to achieve multi-object tracking and matching. The cross microphone array was adopted by the acoustic source localization module to obtain the audio information, and according to the time delay of receiving signals of each microphone, the acoustic source orientation was calculated. The audio-video likelihood function and audio-video importance sampling function were constructed by the audio-video information fusion tracking module, and the importance particle filter was used as the audio-video information fusion tracking algorithm to achieve object tracking. The performance of the algorithm was tested in complex indoor environment. The experimental results show that the tracking accuracy of the proposed algorithm reaches 90.68%, which has better performance than single mode algorithm.
Aiming at the problem of particle impoverishment in the standard particle filter, a particle filter algorithm based on the whale swarm optimization was proposed. In the algorithm, the particles were used to characterize the individual whales so as to simulate the process of whale swarm for searching preys and guide the particles to move to the high-likelihood region. Firstly, the state value of particles in particle filter was taken as the individual position of the whale swarm, and the state estimation of particles was transformed into the optimization of the whale swarm. Secondly, the importance sampling process of particles was optimized through the spiral motion mode of the whale swarm, which made the particle distribution more reasonable. In addition, the optimal neighborhood random disturbance strategy was introduced for the global optimal value in the whale swarm algorithm, and the adaptive weight factor was added in the process of whale position update. Finally, a typical single-static non-growth model was selected for the simulation test. The test results show that compared with the standard particle filter and the particle filter optimized by the gravitational field, the mean square error of the proposed algorithm is reduced by 28% and 9% respectively under the premise of the same particle number, which verifies that the particle filter algorithm optimized by the whale swarm has the higher estimation accuracy, and in the case of fewer particles, the more accurate state estimation can be achieved.
A multiple cameras calibration method based on chess augmented reality university of cordoba (ChArUco) board was proposed for the multiple cameras system with limited or non-overlapping field of view. The ChArUco board was used to calibrate the camera; the global optimization was carried out based on the binocular reprojection error to provide precision guarantee for the subsequent pose transfer between cameras with non-overlapping field of view. Finally, the performance was tested by the spatial point reconstruction. The experimental results show that the average measurement error is 0.11 % within the point distance of 25 cm.
The modulation transfer function area (MTFA) of pinhole imaging and the MTFA relative variation ratio were used as the image surface parameters to quantitatively evaluate the microscopic imaging quality of the board lens. The light spot images located in different fields of view positions were obtained by using the pinhole imaging method to extract the modulation transfer function (MTF) of microscopic imaging system for board lens. The MTF mathematical model of lens system for board lens was established, and the MTFA in sagittal direction and meridian direction of edge field of view as well as the MTFA relative variation ratio were extracted to measure the microscopic imaging definition and image surface flatness of the measured lens. An experiment which was for measuring the board lens was carried out, and the microscopic imaging performance of the measured lens was quantitatively evaluated by using the proposed model and method. The results show that the Lens 2 can obtain the optimal microscopic imaging quality. The definition value of average power spectrum value (APSV), the gray mean gradient (GMG) and the laplacian summation (LS) were calculated respectively from the RGB bitmap images captured by these measured lens. The results show that the maximum parameter value of the APSV, GMG and LS of Lens 2 bitmap images is equal to 2.720 2, 17.024 4 and 94.921 2, respectively. At the same time, the bitmap images have the highest definition, which is consistent with the image surface parameter evaluation results, indicating that the proposed method used in the quantitative evaluation of microscopic imaging performance of board lens is accurate and effective, which is of great significance and engineering value to improve the online image probe design of the on-line visual ferrograph (OLVF).
A MARX cascade circuit laser illumination source for underwater laser range-gated imaging was developed based on the avalanche cascade principle. Compared with the ordinary laser drivers, this MARX cascade circuit had the advantages of narrow output pulse, high peak voltage, short rising edge, high repetition frequency, low cost, small volume and light weight. The pulsed laser illumination source developed by the cascade circuit maintained the miniaturization of illumination source system volume on the basis of realizing the pulse width performance with nanosecond (ns) magnitude. The experiment of range-gated imaging of underwater was carried out by the pulsed illumination source combined with laser shaping and homogenizing optical technology. With a pulse width of 10 ns, the range-gated imaging in the range of 7 times attenuation length under the water was achieved. The improvement of circuits and optics is of great significance to the reduction of volume and cost, and the application of laser range-gated imaging system.
For the actual demands of the aerial electro-optical detection system, firstly, the qualitative and quantitative factors for evaluating the optical image quality were analyzed from the perspective of image information, an image definition evaluation method based on similar feature region extraction was proposed to achieve the matching between the subjective feeling and objective evaluation of the image definition. Then, from the perspective of the optical evaluation of imaging system, the optical transfer function, aberration, transmittance and other factors affecting the imaging quality were analyzed, and according to the multi-band long focal reflective optical system, the experimental results were verified. Finally, combined with the requirements for engineering practice to improve the imaging quality, several aspects that should be given more attention in the development of optical imaging system were pointed out. And for the multi-band long focal reflective optical system, some specific parameter suggestions were given.
In order to achieve accurate extraction of the center of laser stripes during the underwater detection of nuclear fuel rods, an self-adaptive stripes center extraction method for reflective surface of underwater nuclear fuel rods was proposed. According to characteristics of water scattering and object surface high reflections in detection environment, the underwater noise points and reflective noise points were removed to realize segmentation and extraction of laser stripes; the curve fitting of BP neural network and adaptive convolution template generated from light bar geometry information were utilized to realize contour and gray distribution correction of reflective region, so that the gray distribution of light bar section conformed to the Gaussian distribution; the subpixel precision location and extraction of laser stripes center were realized in light bar section direction by gray centroid method. The experimental results show that this method can effectively solve the problems of discontinuous center line and many noise points of reflective surface light bar of measured object. The 3D reconstruction error of point cloud is within 0.2 mm, which ensures accuracy and stability of stripes center extraction and meets the engineering requirements of underwater detection of nuclear fuel rods.
In the process of applying robots to car body spot welding quality inspection, the positioning accuracy of its welding spots was affected by factors such as quality of spot welding operations and car body manufacturing errors, which resulted in actual welding spots did not coincide with designed values. Aiming at the problem that traditional teaching could not perform real-time compensation for welding spot positioning, a welding spots positioning strategy based on binocular vision guided robots was proposed, and a support vector machine regression error compensation model optimized based on improved particle swarm algorithm was constructed to compensate the positioning results. The binocular sensors were installed at the end of the robot, the binocular positioning principle was used to initially locate welding spots, and the measured data and actual data of welding spots position was used as learning samples. The trained error compensation model was used to predict positioning error of the system, and the compensation results were used as the correction value guiding the robot to locate welding spots. The experimental results show that the positioning accuracy after compensation is greatly improved, which verifies the effectiveness of the method.
In order to obtain the high quality all-in-focus imaging in large depth of view, an all-in-focus image reconstruction technology based on single exposure light field imaging and guided filter was proposed. First, the field of view information was collected by the optical field imaging, and the multi-focus image source set was obtained by the optical field reconstruction. Then the guided filter method was used to determine the weight of image fusion at all levels, and finally the image fusion was performed to obtain the all-in-focus image with extremely large depth of field. The experimental results show that the proposed method not only effectively ensures the background consistency, but also keeps the edge retention to reconstruct the all-in-focus image with high quality. Therefore, the proposed technology can be potentially adopted in many applications such as on-site monitoring, geographical exploration, military reconnaissance and unmanned technologies, etc.
In order to provide the accurate initial physical information for numerical simulation of aircraft and missile separation, a missile physical information extraction scheme based on regional Hough transformation was proposed, which used high-speed cameras to extract the positions of marking circle centers on the missile body and tail in the video frame, and calculated the physical information of missile through the coordinate transformation. In frame processing, according to short time interval and negligible change of velocity vector in the frames, a circle search algorithm based on regional Hough transformation was proposed. In view of the fact that the real motion vector is biased rather than uniformly distributed in search window, the search box was fixed shifted. The centering error between predicted region and actual region is less than 5%, the consuming time is reduced by more than 41.6% compared with the traditional algorithm, and the average error between calculated results and actual results does not exceed 2.39%. Also, this algorithm can adapt to the complex backgrounds and meet the timeliness and accuracy requirements of the program.
Semantic information is essential for mobile robots to understand the content of the environment and perform complex tasks. Aiming at the problem that the point clouds constructed by ORB-SLAM2 is too sparse and lacks semantic information, a dense point cloud semantic map of the environment by combining the object detection algorithm with visual SLAM technology was constructed. First of all, the object detection network YOLO v3 and object regularization were used to accurately obtain the 2D label of the object. At the same time, the ORB-SLAM2 algorithm was used to construct the environment's sparse point cloud map. The color image with 2D labels, corresponding depth images, and key frames were used to generate dense point cloud labels with semantic information. Then the graph-based segmentation algorithm was used to segment the dense point cloud, and the point cloud labels were fused with the segmented point cloud so as to construct a dense point cloud semantic map of the environment. The proposed method was tested on the TUM public data set and the experimental results show that the method can construct a better semantic map. Compared with the traditional ORB-SLAM2 algorithm, this system reduces the absolute pose error and absolute trajectory error of the camera by 16.02% and 15.86% respectively, in the process of constructing the map, which improves the mapping accuracy. In order to reduce the storage space of point cloud maps and facilitate mobile robots' navigation and avoidance, the constructed semantic maps are finally converted into octree maps.
TensorRT is a high-performance deep learning and inference platform. It includes a deep learning and inference optimizer as well as runtime that provides low latency and high throughput for deep learning and inference applications. An example of using TensorRT to quickly build computational pipelines to implement a typical application for performing intelligent video analysis with TensorRT was presented. This example demonstrated four concurrent video streams that used an on-chip decoder for decoding, on-chip scalar for video scaling, and GPU computing. For simplicity of presentation, only one channel used NVIDIA TensorRT to perform object identification and generate bounding boxes around the identified objects. This example also used video converter functions for various format conversions, EGLImage to demonstrate buffer sharing and image display. Finally, the GPU card V100 was used to test the TensorRT acceleration performance of ResNet network. The results show that TensorRT can improve the throughput by about 15 times.
Aiming at the problem that the cracked cell in the solar cell module eventually causes the whole cell to break and affect the power generation of the whole component, a method for detecting cracked defects of battery components using convolutional neural network network (CNN), is proposed based on the screening and positioning of the photoluminescence (PL) image of the battery component. The basic idea is to obtain the image of the battery component by using the PL detection technology first, then pre-process the image, filter and locate the target area based on the clustering method, and finally use three convolutional neural network models to detect the defect of the battery, and compare the accuracy. A large number of experimental results verify that the above method can accurately detect the cracking defects of solar cell modules.
The method for tomographic computer generated cylindrical holography of three-dimensional object was researched: the diffracted wavefront on the holographic surface was the superposition of convolution between the cylindrical cross sections of three-dimensional object with different depths and the corresponding point spread functions, and the computer generated hologram could be obtained by recording the interference patterns from the diffracted object wavefront and the reference. The 360° view of the object could be observed from the reconstructed holograms. Firstly, the tomographic computer generated cylindrical holography model of three-dimensional object was built, and the conditions of system point spread function and sampling interval in different directions were derived. Secondly, the impact on the spatial frequency and the system transfer function by the radii and the wavelengths of different cylindrical cross sections was analyzed from both theory and experiments, and the peak signal to noise ratio as well as the mean square error were adopted to evaluate the quality of the reconstructed holograms. Finally, the tomographic computer generated cylindrical holography was used to encode the three-dimensional earth model, which represented the information of different observation angles and depths. The simulation results show that the proposed method has wide applications for 360° full field display of the ordinary three-dimensional objects.
In order to improve the quality of low-light night vision images, a color transfer algorithm based on image segmentation and local brightness adjustment was proposed. The simple linear iterative clustering was combined with K-means clustering to segment the low-light image, and the color component of matching reference image was transmitted to the sub-region of target image by using the uniformity for the brightness of each sub-region and reference image in the YCbCr color space. The contrast value in the texture feature of the target image was taken as the coefficient to adjust the brightness value of the sub-region of the target image, perform the color space conversion and display the color transfer results. A low-light image imaging system was built, and the low-light image segmentation and color transfer were completed. The results show that the improved segmentation algorithm separates different scenes in the image, and the peak signal-to-noise mean of the obtained color low-light image reaches 12.048 dB, which is 2.63 dB higher than the Welsh algorithm.
In order to improve the ability of driverless vehicles to identify objects in the surrounding environment at night, a three-dimensional target detection method for driverless vehicles based on multi-view channel fusion network was proposed. The idea of multi-sensor fusion was adopted, and the target detection was carried out by adding laser radar point cloud on the basis of infrared image. By encoding the laser radar point cloud into a bird’s-eye view form and a front view form, as well as forming a multi-view channel with the infrared night vision image, the information of each channel was fused and complemented, thereby improving the ability of the driverless vehicle to recognize surrounding objects at night. The infrared image and the laser radar point cloud were used as the input of the network. The network accurately detected the position of the target and the category by the feature extraction layer, the regional suggestion layer and the channel fusion layer. The method can improve the object recognition ability of driverless vehicles at night, the accuracy rate in the laboratory test data reaches 90%, and the time consumption of 0.43 fps also basically meets the practical application requirements.